OAuth is easy once, painful forever
A single Claude login is straightforward. Keeping tokens healthy across machines, background jobs, and occasional service restarts is the real work.
Quick context: OAuth is the standard delegated-login protocol many APIs use, and PKCE is a safer OAuth flow for public clients because it avoids shipping a long-lived client secret in the app. In this article, an “object bucket” means S3-style cloud object storage used to sync encrypted token state between services, and “cron fallback” means a scheduled job that periodically checks and refreshes tokens if the primary refresh loop misses.
I hit this wall when local tools worked for one developer but broke for another because refresh happened late, local state drifted, or credentials existed in one place but not the next place that needed them.
That is when auth stopped being “login code” and became an operations system.
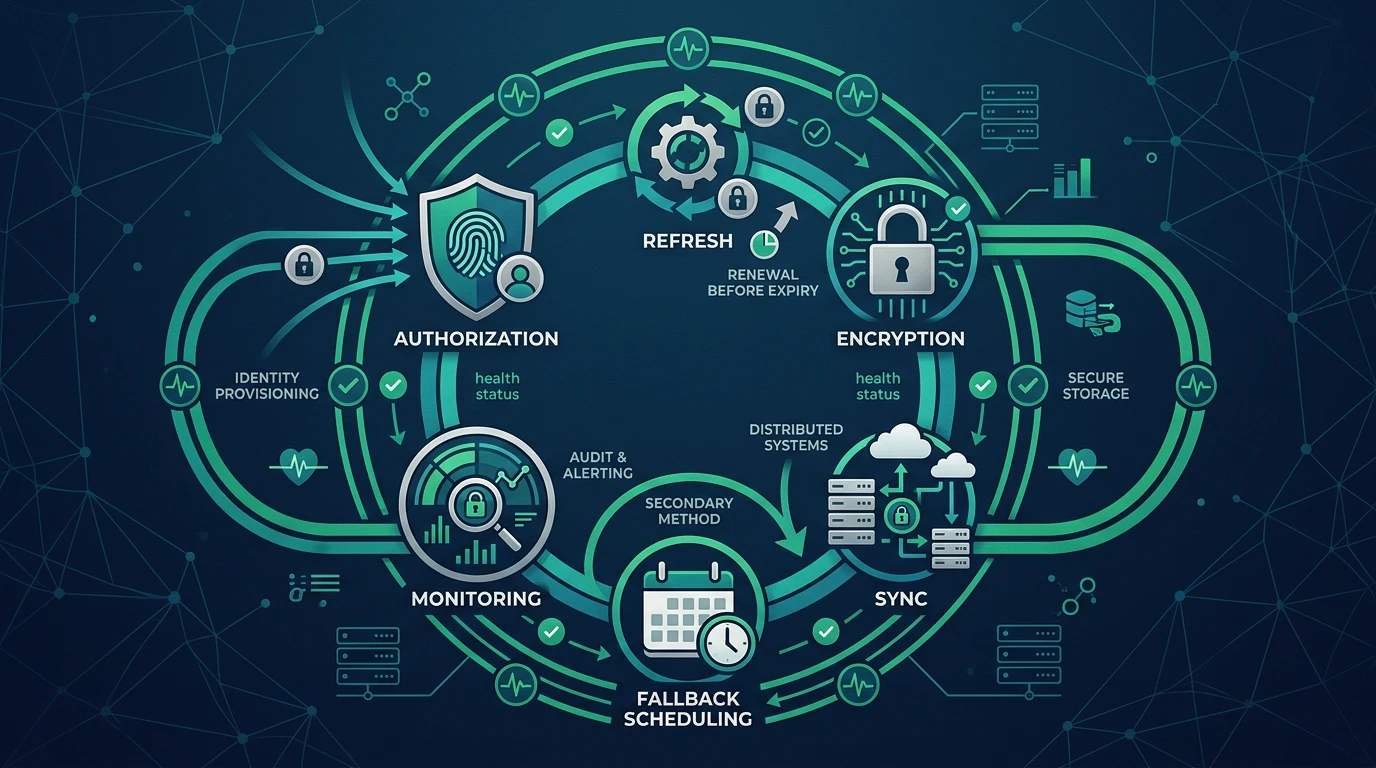
The lifecycle I needed had to cover:
- PKCE-based authorization
- proactive refresh before expiry
- encrypted storage at rest
- cross-environment credential sync
- fallback scheduling when the primary loop misses
- enough observability to debug failures quickly
PKCE as the baseline path
I used PKCE as the default flow because it avoids distributing long-lived client secrets in every runtime environment.
The practical benefit was consistency. Whether auth started from a local dev command or a managed process, the token acquisition path was the same.
I also kept token metadata alongside the credential payload:
- issued-at and expiry
- refresh-at target
- source and last-sync markers
Without metadata, every refresh decision becomes guesswork.
Refresh buffers are non-negotiable
The biggest reliability jump came from refreshing early.
Refreshing at or near expiry assumes perfect clocks, clean network conditions, and no retries. Real systems have none of those.
I now use buffer windows so refresh starts before deadlines:
- normal refresh threshold
- warning threshold
- emergency threshold for aggressive retry
This gave me room for transient failures without dropping into expired-token behavior.
I also rate-limited retry loops. Aggressive retries can turn a provider hiccup into your own outage by flooding auth endpoints.
Encrypted storage and explicit trust boundaries
Tokens live beyond one process, so storage decisions matter.
I encrypt credentials before writing them anywhere durable. That includes local files in dev and object storage in shared environments.
I treat object storage as transport and persistence, not trust. A bucket is not security by itself. Encryption, key handling, and access controls still carry the real load.
This sounds strict, but it kept the architecture honest. If an integration step depended on “nobody will read this bucket,” it failed review.
Bucket sync and drift control
I used bucket sync to make tokens portable between components that needed shared auth state. The point was not convenience for its own sake. It was reducing manual re-auth workflows that break automation.
The hard part was drift:
- component A refreshed and wrote state
- component B was still using stale state
- both thought they were authoritative
I solved that with versioned metadata and write-order checks. Last-write-wins without context is a good way to lose fresh credentials.
I also logged sync outcomes with enough detail to trace problems:
- sync attempted
- sync skipped with reason
- sync failed with retriable/non-retriable classification
This let me debug issues without exposing secrets.
Cron fallback as recovery, not primary path
Primary refresh loops fail sometimes. Processes restart. Jobs get stuck. Schedulers drift.
I added cron-based fallback refresh to recover token state when the main loop missed cycles. That cut down on manual interventions.
Important constraint: fallback stays secondary. If cron becomes the primary behavior, you are masking deeper issues in the main lifecycle.
I keep fallback simple:
- check token freshness
- refresh if below threshold
- persist and sync
- emit clear health signal
No extra business logic there. Recovery code should stay boring.
Observability that operators can actually use
The first implementation had logs, but not useful ones. I could see “refresh failed” without knowing whether the cause was auth, storage, sync, or clock drift.
I added lightweight health and metrics around each stage:
- token age and time-to-expiry
- last successful refresh timestamp
- refresh failure counts by category
- sync success/failure trend
I also added alert thresholds for “approaching expiry with repeated refresh failure.” That catches silent degradation before users see auth errors.
Operational lessons I would not skip again
A few mistakes were predictable in hindsight.
First, refresh logic without jitter can align multiple workers to refresh at the same time. That produces avoidable spikes.
Second, encryption design must include key rotation from day one. Retrofitting rotation is painful.
Third, manual “just rerun login” instructions are fine for day one and terrible for ongoing reliability.
The lifecycle improved when I treated these as system design concerns, not cleanup tasks.
What changed after this work
The biggest change was confidence. Auth stopped being a fragile, person-dependent process.
- tokens stayed fresh through normal process churn
- encrypted state moved safely across components
- fallback handled missed cycles without panic fixes
- incidents were diagnosable from telemetry instead of guesswork
This did add complexity. There are more moving parts now than with a manual login script. But the complexity is structured and observable.
For teams running AI features in production-like environments, that tradeoff is worth it. The cost of “simple” auth workflows shows up later as downtime and manual firefighting.
If I were extending this next, I would invest in automated chaos tests for auth disruptions: delayed clock, intermittent object storage failure, revoked refresh token, and scheduler pause. Those cases are where lifecycle systems either prove themselves or unravel.