Why I built a translation proxy in the first place
Every provider says their API is “OpenAI-compatible” right up until you stream tokens, pass tool calls, or switch auth modes. Then the differences show up fast.
Quick context: Anthropic, OpenAI, and Gemini are different AI model providers. Each provider exposes similar capabilities, but the request and response formats are not identical. A “translation proxy” is a service that sits between your app and those providers so your app can send one stable format while the proxy translates to each provider’s expected format. “Streaming” means returning generated text incrementally token-by-token instead of waiting for one final response.
In my stack, clients wanted a stable integration surface while backend routing stayed flexible. I needed to support Anthropic-style requests, OpenAI-style payloads, and Gemini-style behavior without forcing each client to learn all three dialects.
The first naive approach was to put if provider === ... logic in every service that called models. That lasted about a week. It made releases risky and turned provider experiments into app-wide refactors.
So I pulled translation out into a dedicated proxy layer.
The design rule: clients talk one language
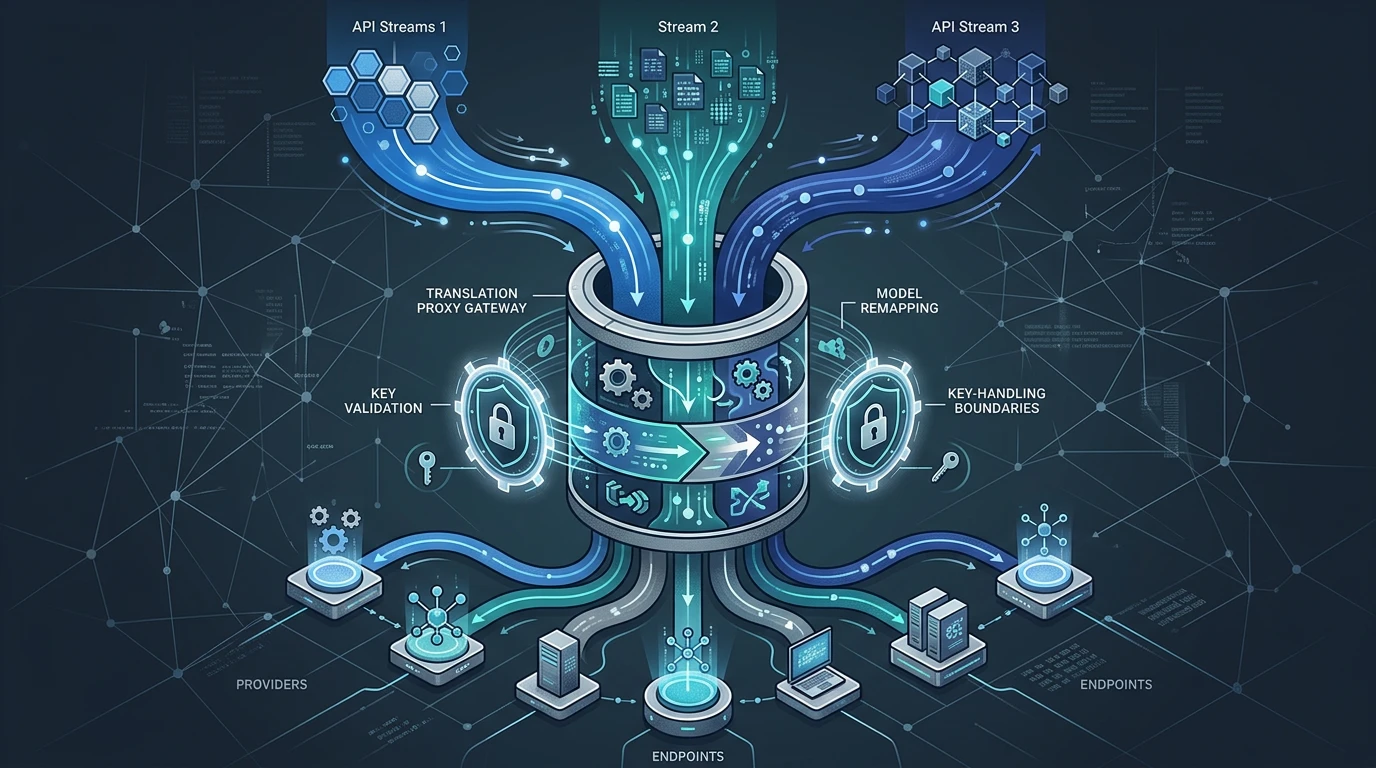
The proxy does five jobs:
- translate request shapes
- remap logical model names to provider-specific names
- route to the right backend
- keep streaming behavior compatible
- enforce key-handling boundaries
I treat each of those as a separate module, not one giant request handler. If you collapse them into one file, small changes break unrelated behavior.
One practical example: model remapping should not care about stream framing, and stream framing should not care about whether keys are passthrough or proxy-owned. Separation made debugging much less painful.
Translation details that mattered more than expected
Request translation sounds straightforward until you hit edge features.
The rough spots were usually here:
- system prompt location differences
- tool/function call formats
- message role conventions
- error payload shape and status mapping
I stopped trying to build a universal “perfect abstract schema.” Instead, I built explicit adapters per dialect with tests around known tricky cases.
That gave me clear ownership. When Anthropic-style tool payloads changed, I edited the Anthropic adapter. I did not have to retest the entire world mentally before touching a line.
Streaming is where most proxies quietly break
Non-streaming translation is easy to demo. Real products stream.
If the proxy re-chunks tokens incorrectly or delays flush behavior, clients feel laggy even when backend model latency is fine. Worse, some clients parse stream events by type, and small event-shape differences crash parsing.
I made streaming a first-class contract:
- preserve incremental delivery semantics
- normalize event types consistently
- avoid buffering that destroys token cadence
- translate provider-specific stream metadata where needed
I also test cancellation and early disconnects. Those edge paths are where resource leaks show up.
Model remapping and routing as control-plane concerns
I do not let clients hard-code provider model IDs unless there is a strong reason. Clients request logical names, and the proxy maps those names based on configuration.
That gave me a safer rollout path. I can move fast-general from one backend model to another without touching every consumer.
Routing works the same way. Some routes are explicit from client input. Others follow policy defaults. Either way, decisions are logged so behavior is inspectable when someone asks, “Why did this request go there?”
Hidden routing logic is operational debt. You pay for it during incidents.
Key handling had to be explicit, not implied
This was the part I did not want to get “mostly right.”
I support two modes:
- proxy-owned keys (single-tenant server credentials)
- passthrough keys (multi-tenant caller-provided credentials)
The rules for each mode are different for logging, retries, rate limiting, and audit trails. Mixing them casually is dangerous.
I treat mode selection as required configuration, not an optional hint. If the request is ambiguous, fail early. Ambiguity around credentials leads to billing mistakes first and security issues second.
I also keep logs strict: no raw key material, no accidental header dumps.
Failure modes I planned for
Provider APIs change. They always do.
So I built for ongoing adaptation:
- adapter-specific error translation so client behavior stays stable
- feature flags for incremental rollout of new provider capabilities
- compatibility tests around the edge cases that broke before
One lesson: fallback behavior must be obvious. Silent fallback to a different provider can hide incidents and create compliance problems. If routing changes, I want that visible.
Another lesson: generic interfaces can erase useful provider features. I now allow controlled provider-specific escape hatches when the alternative is lowest-common-denominator behavior.
What improved after adopting this pattern
Client teams now integrate once against a stable surface instead of chasing provider churn. That alone reduced friction.
Operationally, the proxy gave me one place to reason about:
- streaming correctness
- model migration
- key mode policy
- provider outage response
It did not remove complexity. It moved complexity to a layer where it can be managed deliberately.
Tradeoffs I still live with
A translation proxy is not “set and forget.”
- adapters need updates as upstream APIs evolve
- compatibility tests need maintenance
- the proxy becomes a critical dependency and needs good observability
I accept that because the alternative is distributed complexity in every caller.
If I were extending this next quarter, I would add stronger contract tests generated from real production traces (sanitized), especially for streaming edge events. Those traces catch subtle regressions earlier than synthetic payloads alone.
The core takeaway is simple: interoperability is a product feature. If you want provider flexibility without breaking clients every month, you need a real translation layer, not scattered conditionals and optimism.