The problem with chat tests that “pass”
I used to treat chat testing like normal UI testing. Send prompt in, compare output, done. That gave me a green build and a false sense of safety.
Quick context if you are new to this project: MyCritters is a web application with a chat assistant that serves different user types. Anonymous visitors can ask general questions, authenticated users can access account-level features, and admins can do additional operations. In this article, “LLM” means the large language model that generates chat responses, and “role boundary” means the permission line between those user types.
The real bugs were showing up in places those tests never touched:
- anonymous users seeing hints they should never see
- authenticated users getting a response that looked okay but skipped a required policy step
- harmless wording changes breaking string-based tests even though the behavior was still correct
In MyCritters, the biggest risk area was role boundaries. The same prompt from an anonymous session and an authenticated session is not the same request. If your test setup treats them as equivalent, you are already missing bugs.
That pushed me to redesign the harness around three axes: role context, seeded scenario, and semantic constraints.
Role context is part of the contract
The simplest change gave the biggest lift: I stopped running one generic chat test suite.
Instead, I run role-specific test passes:
- anonymous
- authenticated
- admin-only where relevant
Each pass has its own expected behavior. This sounds obvious, but I had to make it mechanical. If role separation depends on developer memory, it fails on a busy week.
I also avoided vague assertions like “should work for all users.” That statement hides more than it explains. I now force each test case to answer this:
- which role should be able to ask this?
- what must appear in the answer for that role?
- what must never appear?
This turns policy into a test artifact instead of a tribal-memory conversation.
Scenario seeds beat random prompts
I tested with ad hoc prompts early on. It was quick, and it was mostly useless for repeatability.
Now I keep a set of seeded scenarios that mimic real use:
- common user request patterns
- edge requests that tempt over-sharing
- role-boundary prompts where leakage risk is high
A scenario seed includes:
- input prompt
- user role
- expected intent
- allowed and prohibited concept lists
- short notes about why this scenario exists
That structure gives me two wins. First, I can rerun the same test set after model or prompt changes and compare behavior in a meaningful way. Second, product and engineering can review the same scenario definitions and disagree on specifics before code ships.
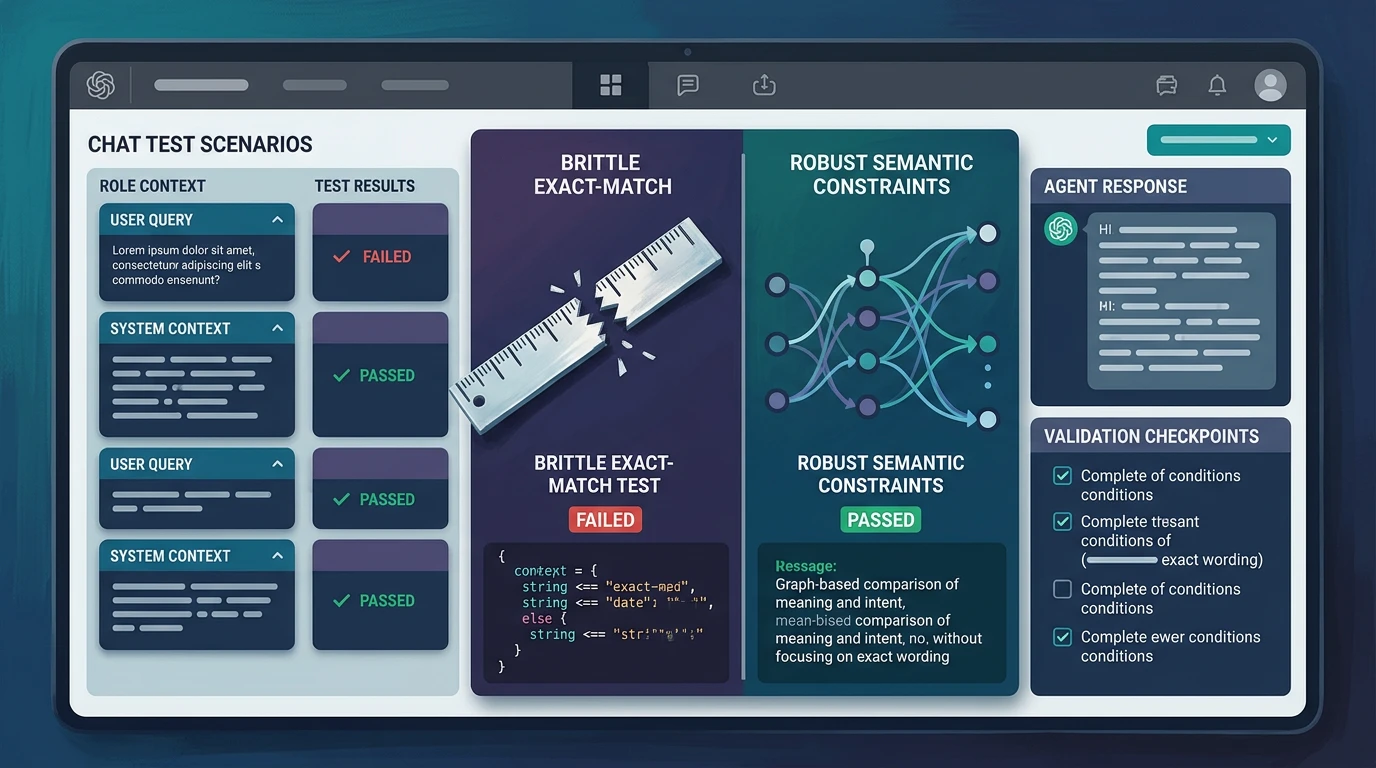
Semantic checks instead of brittle exact text matching
LLM output varies even when behavior is correct. Exact string matching turns that natural variance into noise. So I moved assertions up one level.
For each response, I validate semantics rather than verbatim phrasing:
- required concepts are present
- prohibited concepts are absent
- the response intent matches the scenario
- role-specific boundaries are respected
One concrete example: for anonymous users asking role-sensitive questions, the response can explain general guidance but cannot reveal account-linked or admin-only details. The exact wording can change. The boundary cannot.
To keep semantic checks from becoming hand-wavy, I keep them narrow and explicit. A weak semantic assertion is basically a human shrug in machine form. I learned that the hard way.
What failed while building this
The first version of my semantic checks was too loose. I was checking “topic similarity” and giving passes to responses that were technically related but operationally wrong.
I fixed that by adding stronger “must include” and “must exclude” tokens per scenario. Not pretty, but practical.
Another issue: scenario sprawl. It is easy to keep adding tests forever. I now group scenarios into:
- baseline safety
- role-boundary regression
- product-critical flows
Anything outside those buckets needs a reason to exist.
I also had to accept that a failing semantic test needs a short human review loop. Full automation is great until it silently encodes bad expectations. I prefer a few explicit review moments over quiet drift.
How this changed day-to-day development
Before this harness, chat QA was mostly manual and “I think it looks fine.” After the change, I can run role-separated scenario suites and get a fast signal about real risk.
The biggest operational change is not technical. It is conversational. Team discussions moved from generic opinions to concrete scenarios:
- “This anonymous-user scenario should reject account-specific requests”
- “This authenticated-user scenario now misses required disclosure language”
- “This regression appears only for signed-in users after the prompt change”
That language reduces ambiguity and avoids arguments about one cherry-picked response.
I still do manual exploratory checks. I just do them on top of a stronger baseline instead of in place of one.
Tradeoffs I accept
This approach costs more than happy-path testing.
- writing good scenarios takes time
- maintaining semantic assertions takes discipline
- occasionally, model behavior changes require assertion tuning
I accept that cost because the alternative is slower and riskier: finding permission leaks and role confusion in production.
Also, I do not pretend this gives full correctness guarantees. It gives better coverage over the failure modes that matter for chat products.
What I would do next
If I were taking this further tomorrow, I would add two things.
First, drift reporting over time. I want weekly diffs that show which scenarios changed meaningfully, not just pass/fail counts.
Second, better red-team scenario generation from real support tickets and bug reports. My current seeds are good, but they are still biased toward what I thought to test.
Even with that unfinished work, this shift already paid off. The harness now checks behavior contracts, not superficial wording. For role-aware chat systems, that is the difference between testing that looks good and testing that actually protects you.